Woah. Da stellen sich mir wahrhaftig die Nackenhaare auf.
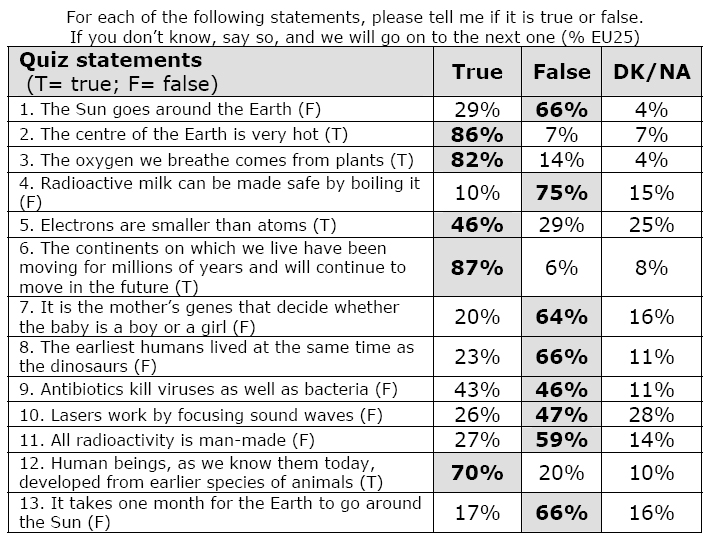
Die "Leitersprossen" der DNA bestehen
nicht aus drei "Ziffern". Einzelsträngige DNA besteht aus einem "Rückgrat" aus Desoxyribose-Molekülen und Phosphatresten. An die Desoxyribose-Moleküle kann eine von vier Basen gebunden sein (
Adenin,
Thymin,
Guanin,
Cytosin). Im Genom liegt
DNA doppelsträngig vor, wobei jede der Basen mit der komplementären Base gepaart vorliegt. Adenin bindet an Thymin, Guanin an Cytosin. D. h. die "Leitersprossen" bestehen entweder aus A-T oder C-G.

(
Bild-Quelle)
Ein
Gen besteht aus einer Abfolge von Nukleotiden (eine der vier Basen + Desoxyribose + Phosphatrest). Wird es abgelesen, wird es zunächst in RNA "umgeschrieben" (transkribiert) und dann in eine Reihe von Aminosäuren (= Protein) "übersetzt" (translatiert).
RNA ist ein einzelsträngiges Molekül, das ähnlich wie einzelsträngige DNA aufgebaut ist. Anstelle von Desoxyribose enthält das "Rückgrat" aber Ribosemoleküle und
Thymin ist durch
Uracil ersetzt. Bei der Transkription wird eine Negativ-Kopie des kodierenden DNA-Strang aus RNA erstellt (messengerRNA), wobei jeweils die komplementären Basen verwendet werden, d. h.
A wird zu
U,
T zu
A,
G zu
C,
C zu
G.
Bei der
Translation wird die mRNA-Sequenz schließlich in eine Aminosäure-Sequenz umgesetzt. Dabei entsprechen jeweils drei aufeinander folgende Basen (ein
Codon) einer bestimmten Aminosäure. Es sind 64 verschiedene Codons möglich (an drei Stellen kann jeweils ein von vier Basen stehen: 4
3 = 64), die jeweils eine bestimmte Aminosäure kodieren, bzw. Start- (ein Codon) und Endpunkt (zwei Codons) der Translation bestimmen. Es gibt nur 20 direkt kodierte proteinogene Aminosäuren (nachträgliche Modifikationen dieser Aminosäuren kommen vor), d. h. viele der Aminosäuren werden durch zwei oder mehrere verschiedene Codons kodiert.
Was der Autor hier also berechnet, ist nicht die Zahl der möglichen "Leitersprossen", die ist und bleibt 4, sondern die Zahl möglicher Basen-Tripletts oder Codons.
Weiter geht's:
Wir stellen uns also jetzt eine Strickleiter mit 64 Leitersprossen vor, die alle eine andere Farbe haben. Wie viel Möglichkeiten gibt es, diese64 Leitersprossen anzuordnen.
64-Fakultät = 64! = 1*2*3*...*62*63*64
64! kann ein Taschenrechner gerade noch berechnen. Wir erhalten rund10^89, eine 1 mit 89 Nullen. Das ist etwa die geschätzte Zahl der Atome des Weltalls, vielleicht ist sie es ja auch, wer weiß das schon.
Seufz.
Nehmen wir mal an, ich hätte 64 Karten mit verschiedenen Symbolen darauf und würde die in einen Sack stecken. Jetzt ziehe ich blind eine Karte heraus und lege sie auf den Tisch. Darauf kann eins von 64 Symbolen sein. Nun ziehe ich eine zweite Karte. Da ich ja schon eine Karte aus dem Sack gezogen habe, kann ich nun nur noch eine von 63 Karten ziehen. Die gezogene Karte lege ich auf den Tisch und ziehe erneut eine Karte. Eine aus 62 Karten. Dann eine aus 61 Karten, 60, 59, ... 1. Um die Anzahl verschiedener Anordnungen, die ich ziehen könnte, zu erhalten, müsste ich also 64 x 63 x 62 x 61 x 60 x ... x 1 oder in Kurzform 64! berechnen.
Aber a) gibt es nur 4 verschiedene Basen und nicht 64, b) gibt es von jeder Base so viele wie man will, darum berechnet man die Anzahl möglicher Tripletts auch mit 4 x 4 x 4 und nicht 4 x 3 x 2 und c) was soll der Unsinn? Es gibt 64
64 Möglichkeiten, wie Codons in einer 64 Codon-langen Sequenz angeordnet sein könnten. UND?
Wir wollen nun wissen, wie lange göttin Evolution bräuchte, alle diese Möglichkeiten (Lebewesen) zu erzeugen und auszutesten (welche nur 64 Leitersprossen in der DNS haben; schon ein Parasit ohne Zellwand- Mycoplasma genitalium - hat 580 070 Leitersprossen, Basenpaare). Wir billigen jedem Lebewesen eine Sekunde Lebenszeit und eine Lebensraum von 1mm² zu.
Die Oberfläche der Erde beträgt grob 500 Millionen = 5*10^8 km², wir sind großzügig und sagen 10^9 km².
1 km² = 10^6 * 10^6 mm². Folglich besteht die Oberfläche unsere Planeten aus weniger als 10^21 mm².
Ein Jahr in Sekunden: 365 * 24 * 60 * 60 ergibt rund 31 Millionen. Wir sind großzügig und sagen 100 Millionen = 10^8 Sekunden.
In einer Sekunde können also (in unserer gewählten Methode) 10^21Mutanten erzeugt und ausgetestet werden, folglich in einem Jahr 10^21 * 10^8 = 10^29.
Das Weltall soll ein Alter von 10-20 Milliarden Jahren haben. Wir sind großzügig und sagen 100 Milliarden = 10^11 Jahre.
Werden nun in einem Jahr 10^29 Mutanten erzeugt und ausgetestet, so in 10^11 Jahren
10^11 * 10^29 = 10^40.
Wäre also das Weltall 100 Milliarden Jahre alt und wären in jeder Sekunde so viel Mutanten erzeugt und ausgetestet worden, wie auf jedem Quadratmillimeter unseres Planeten passen, dann wären erst 10^40 von 10^89 Mutanten getestet worden, also der 10^89 / 10^40 = 10^49 -ste Teil (auch für diese Zahl haben wir kein Wort).
Und wäre das Weltall so viel Jahre alt wie es Sekunden alt ist, es wäre noch immer nicht die Hälfte erreicht. Ein Bakterium aber hat nicht bloß die 64 hier vorgerechneten Leitersprossen, sondern über eine Million. q.e.d.
Mann, muss das Leben einfach sein, wenn man so ein beschränktes Denkvermögen hat.
Die tatsächliche Anzahl möglicher Kombinationen von vier Basen in einer 3 Milliarden langen Sequenz (wie das menschliche Genom) beträgt 4
3.000.000.000. Das ist eine riesige, RIESIGE Zahl. Nicht so popelig wie 10
89. Warum ist das trotzdem egal?
Weil keiner behauptet, 3 Milliarden Nukleotide hätten sich einfach so aneinandergelagert und *plopp*, plötzlich war da ein Mensch (außer den Kreationisten, die behaupten, Gott hätte es genau so gemacht).
Das Problem mit dieser Betrachtungsweise ist zweifach.
Zum einen ist sie sozusagen "von hinten". Es wird eine einzige Sequenz betrachtet, so getan, als wäre diese eine Sequenz von Anfang an das Ziel gewesen und dann die Wahrscheinlichkeit berechnet, mit der diese einzelne Sequenz zufällig in einem einzigen Schritt entstanden sein könnte.
Ich habe keine Ahnung, wie viele verschiedene Tier- und Pflanzenarten, Bakterien und Pilze es seit der Entstehung der Erde gegeben hat. Alle haben eine andere Genomsequenz. Die Individuen einer Art haben (fast) alle unterschiedliche Sequenzen. So zu tun als wäre nur eine einzige Sequenz möglich, ist einfach falsch. Die Evolutionstheorie behauptet ja eben gerade nicht, dass von Anfang an z. B. der Mensch das Ziel der Evolution gewesen sei, die Evolutionstheorie besagt, dass Evolution ungerichtet verläuft. Es ist eben keine Lotterie, bei der nur eine Zahlenkombination gewinnt.
Der zweite grundlegende Fehler besteht in der Kleinigkeit der fehlenden Einbeziehung von natürlicher Selektion. Die "Kurzformel" der Evolutionstheorie ist
random mutation + natural selection. Man kann doch nicht die eine Hälfte der Rechnung weglassen und sich dann beschweren, dass das Ergebnis nicht stimmt!
[Bringen Leute, die solche "Berechungen" anstellen, auch einen neuen Fön zurück in den Laden, weil er nicht funktioniert, wenn sie den Stecker nicht in die Steckdose gesteckt haben?]
Den Unterschied, den die Einbeziehung von natürlicher Selektion auf solche Berechnungen hat, demonstrierte
Richard Dawkins, ein britischer Evolutionsbiologe, mit dem "
Weasel Program".
Er wählte die Hamlet-Zeile "METHINKS IT IS LIKE A WEASEL" als Zielsequenz. Es gibt 27
28 (~ 10
40) Kombinationen einer 28 Zeichen lange Kette, die aus 27 (26 Buchstaben + Leerstelle) möglichen Zeichen aufgebaut sein kann. Wie Herr T. in seiner "Berechnung" ja schon demonstriert hat, würde es sehr, sehr lange dauern, durch reines Ausprobieren auf diese bestimmte Kombination "METHINKS IT IS LIKE A WEASEL" zu kommen, selbst wenn pro Sekunde Millionen von Kombinationen generiert würden.
Das Weasel-Programm beinhaltet aber einen entscheidenden Unterschied. Es wird eine Zufallskombination aus Buchstaben/Zeichen generiert. Diese wird immer wieder verdoppelt und bei jeder Vervielfältigung kommt es mit einer gewissen Wahrscheinlichkeit zu einem Fehler, einer "Mutation". Das Computerprogramm wählt nach jeder Generation diejenige mutierte Buchstabenkombination aus, die der Zielphrase am ähnlichsten ist, und vervielfältigt nun diese. In Dawkins Worten (The Blind Watchmaker, 1986):
We again use our computer monkey [Anm.: Dies bezieht sich auf das Unendlich-viele-Affen-Theorem, nachdem ein Affe, der unendlich lange zufällig auf einer Tastatur herumtippt, mit an Sicherheit grenzender Wahrscheinlichkeit irgendwann z. B. die Werke Shakespeares getippt haben wird], but with a crucial difference in its program. It again begins by choosing a random sequence of 28 letters, just as before ... it duplicates it repeatedly, but with a certain chance of random error – 'mutation' – in the copying. The computer examines the mutant nonsense phrases, the 'progeny' of the original phrase, and chooses the one which, however slightly, most resembles the target phrase, METHINKS IT IS LIKE A WEASEL.
In dem die Zeichen beibehalten werden, die der Zielphrase entsprechen, und die restlichen Zeichen immer wieder zufällig durch andere Zeichen ausgetauscht, wird die Zeichenfolge mit jeder "Generation" der Zielphrase immer ähnlicher ("cumulative multi-step-selection"):
Generation 01: WDL MNLT DTJBKWIRZREZLMQCO P
Generation 02: WDLTMNLT DTJBSWIRZREZLMQCO P
Generation 10: MDLDMNLS ITJISWHRZREZ MECS P
Generation 20: MELDINLS IT ISWPRKE Z WECSEL
Generation 30: METHINGS IT ISWLIKE B WECSEL
Generation 40: METHINKS IT IS LIKE I WEASEL
Generation 43: METHINKS IT IS LIKE A WEASEL
Während ein Computerprogramm, das zufällig Zeichen-Reihen erstellt, diese dann mit der Zielsequenz vergleicht und bei nicht 100 %-iger Übereinstimmung wieder verwirft, um eine neue zufällige Zeichen-Reihe zu generieren ("single-step-selection"), möglicherweise heute noch nicht bei der Zielphrase angekommen wäre, selbst wenn es gleichzeitig mit der Entstehung des Universums gestartet wurde, brauchte Dawkins Weasel-Programm nach seiner Aussage das erste Mal etwa eine halbe Stunde und 43 Generationen, um "METHINKS IT IS LIKE A WEASEL" zu generieren (als er das Programm später von
BASIC in
PASCAL umgeschrieben hatte, brauchte es nur noch 11 Sekunden).
Dieses Computer-Programm ist insofern natürlich kein gutes Modell für Evolution, als dass es eine bestimmte Zielphrase gibt. Aber es zeigt sehr gut den ausgeprägten Effekt, den natürliche Selektion hat (was auch genau das ist, was Dawkins mit diesem Programm demonstrieren wollte) und ist mit Sicherheit ein besseres Modell für Evolution als die "Berechnungen", die Herr T. oder andere Kreationisten anstellen.
Dawkins selbst zu den Limitationen des Programms:
Although the monkey/Shakespeare model is useful for explaining the distinction between single-step selection and cumulative selection, it is misleading in important ways. One of these is that, in each generation of selective 'breeding', the mutant 'progeny' phrases were judged according to the criterion of resemblance to a distant ideal target, the phrase METHINKS IT IS LIKE A WEASEL. Life isn't like that. Evolution has no long-term goal. There is no long-distance target, no final perfection to serve as a criterion for selection, although human vanity cherishes the absurd notion that our species is the final goal of evolution. In real life, the criterion for selection is always short-term, either simple survival or, more generally, reproductive success.
Ich hatte etwas ähnliches auch in dem Forum geantwortet, in dem Herr T. sein Mutantenzahl-Berechnung gepostet hatte, mittlerweile existiert aber interessanterweise nur noch das Ausgangspost, die Antworten sind weg (vielleicht im Archiv gelandet? Interessiert mich nicht genug, um nachzuschauen.). Ich kann aber verraten, dass Herr T. sich nicht überzeugen ließ.
Wie überraschend.
MfG,
JLT



 Evolution
Evolution Evolution
Evolution